Breaking Latency Barriers in Stock Trading with AMD Xilinx AAT and DG Low-Latency IP Cores
Join us in this exciting article where we showcase the integration of our Low-latency network IP suites with AMD Xilinx’s cutting-edge Accelerator Card and the Accelerated Algorithmic Trading system, AAT.
Discover how this integration revolutionize1s the FinTech industry by overcoming latency limitations, specifically in High-Frequency Trading (HFT) applications.
We delve into the primary application of the Trade Engine in HFT, explaining how market data is received, processed, and used to capitalize on small price variations. By incorporating our Low-latency IPs into AAT, we significantly reduce system latency.
Learn about the latency associated with each transfer direction and explore the advantages of designing hardware for optimal latency and resource utilization.
We are thrilled to introduce the integration of our Low-latency IP suites with the Xilinx AMD Algorithmic Trading system.
Xilinx AMD has been recognized for its cutting-edge hardware-based design solutions. Their Algorithmic Trading system, known as AAT, has already revolutionized the FinTech industry by overcoming latency limitations.
Now, we take this innovation even further by showcasing how our Low-latency IP enhances the system’s latency.
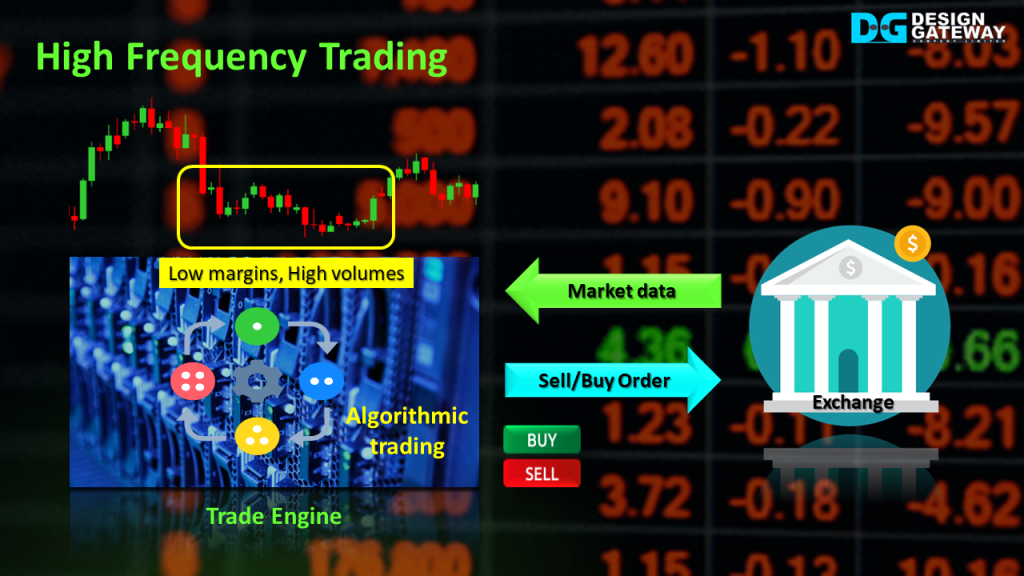
Application of the Trade Engine in a trading strategy : High-Frequency Trading (HFT)
In HFT, the Trade Engine receives market data directly from the exchange through the fastest available route. This ensures minimal latency in receiving the data.
Once the market data is received, Algorithmic Trading strategies are executed to process the incoming data and track price changes for each security.
Unlike other trading approaches that focus on significant price movements, HFT is designed to capitalize on small price variations for individual securities. It aims to send buy or sell orders at fast speeds, aiming to be the first to acquire the targeted security.
Although the profit margins per trade may be small, HFT compensates through high trading volumes. This approach of high-volume trading with small-sized orders helps mitigate the impact of prices on the exchange, allowing HFT traders to take an advantage of even the smallest price differentials.

Algorithm Trading solutions for HFT
The simplest solution involves designing the algorithm on general-purpose computers using software. This approach triggers the order generator when the price meets the specified criteria. With this solution, the latency time from receiving market data to sending the order typically ranges in milliseconds.
second solution involves utilizing high-performance computers equipped with smart NIC located at a Colocation facility. This setup significantly reduces latency time to the microsecond range.
The final solution is to utilize accelerator cards with an accelerator system installed at a Colocation facility. This advanced solution achieves the best latency time, typically in the nanosecond range. By utilizing accelerator cards, it increases a chance of outperforming competitors and achieving success in HFT applications.
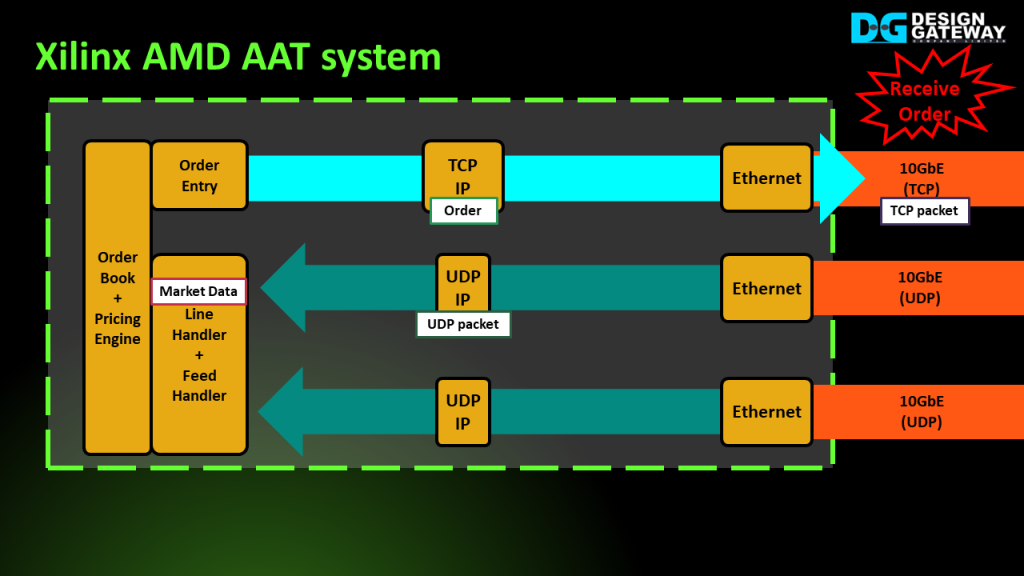
Xilinx AMD offers the Accelerated Algorithmic Trading system (AAT), which can be executed on the Alveo accelerator card.
The AAT system consists of various hardware blocks designed using HLS, except for the Ethernet block, which is an IP core provided by Xilinx. This design flexibility allows users to modify the algorithm to accommodate different market data specifications as needed.
The AAT system utilizes three Ethernet connections: two for receiving the market data stream via the UDP protocol and the remaining one for transmitting the order via the TCP protocol.
The UDP packets are transferred to the UDPIP module via the Ethernet block for extracting the market data. Following this, the hardware engine decodes the market data according to the standards set by the CME.
The example design also incorporates ticker logic, which detects specific conditions in the market data. Once the condition is met, the Order Entry block generates the corresponding order data. This order data is then encapsulated into a TCP/IP packet using the TCPIP module.
Finally, the TCP/IP packet containing the order information is sent out through the Ethernet connection.
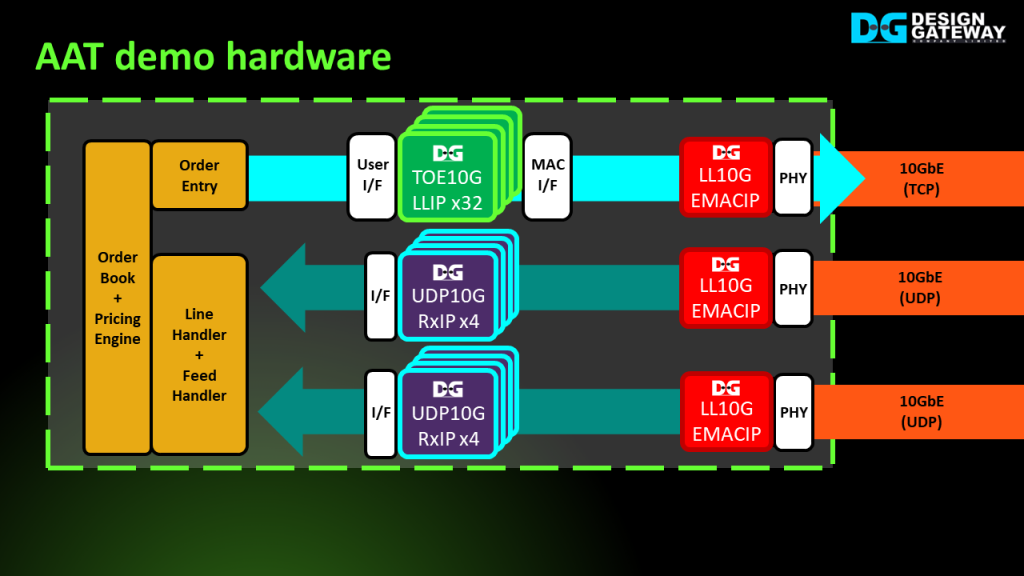
To achieve lower latency, we have integrated our Low-latency IP suites into the AAT.
Firstly, replace the Ethernet block with the LL10GEMAC IP for Ethernet MAC function.
Secondly, replace the UDPIP block with the UDP10GRx IP for UDP packet reception.
Finally, replace the TCPIP block with the TOE10GLL IP for TCP/IP packet transmission.
By integrating these low-latency IPs, we significantly reduce latency of the system.
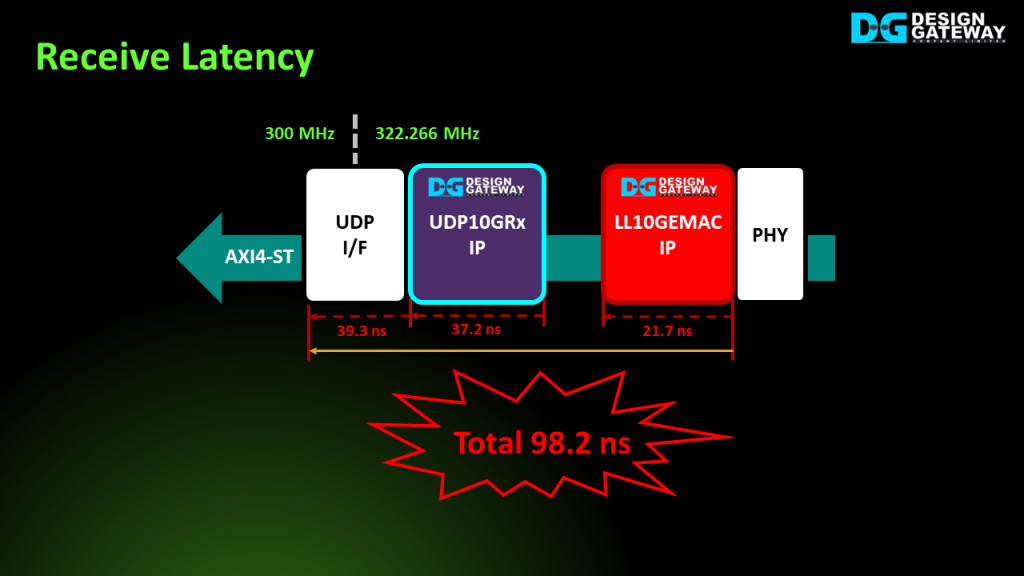
On the receive path, which operates based on a user clock frequency of 300 MHz, the LL10GEMAC IP shows a latency time of 21.7 ns.
Also, the UDP10GRx IP, along with its adapter logic for clock domain conversion, introduces a latency of 37.2 ns and 39.3 ns, respectively.
Combining these latencies, the total latency of the receive path, from the Ethernet MAC interface to the user interface, is 98.2 ns.
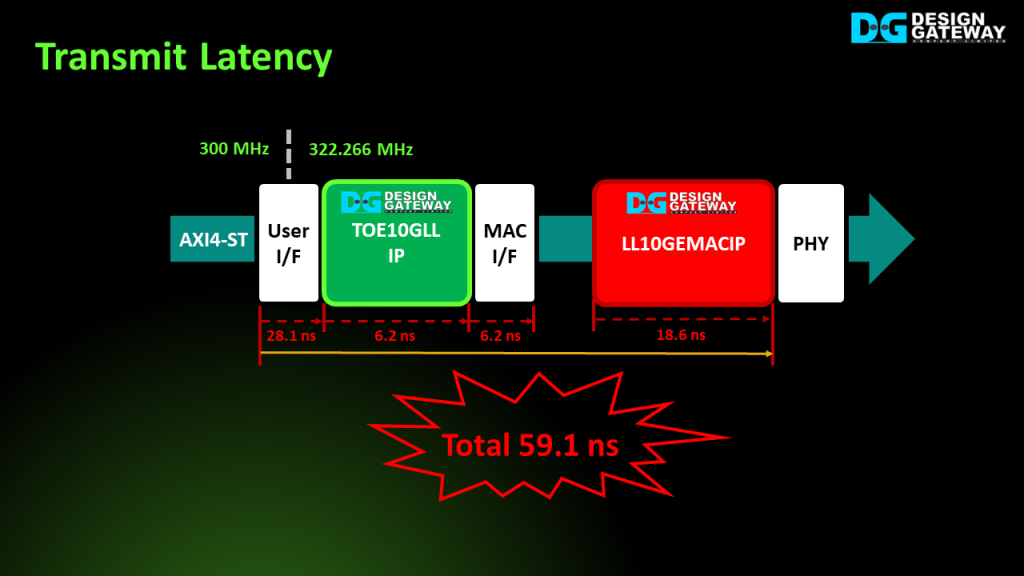
On the transmit path, the latency is measured in the process of TCP order message transmission.
The TOE10GLL IP and its adapter for interface with the user show latency times of 28.1 ns and 6.2 ns, respectively. To support multiple TCP sessions, we utilize multiple TOE10GLL IPs, which are integrated with an adapter for interface with the EMAC.
The latency of the EMAC adapter and LL10GEMAC IP introduces a latency of 6.2 ns and 18.6 ns, respectively. The total transmit latency time amounts to 59.1 ns.
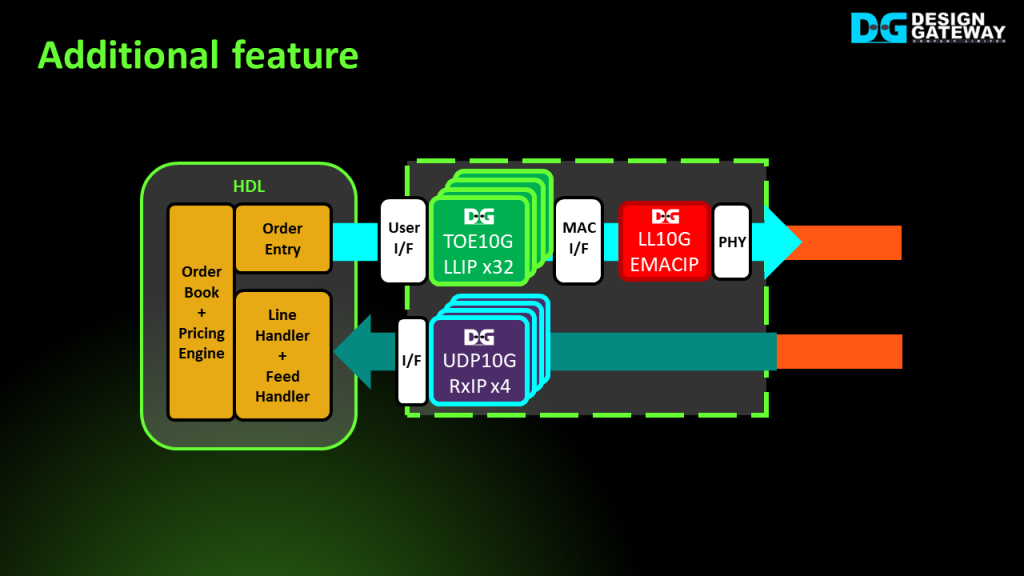
While HLS offers flexibility in porting designs to match various standards, it may not always provide optimized latency and resource utilization.
To achieve the lowest possible latency while minimizing resource usage, it is recommended to design the hardware for processing market data using HDL.
Contact us for more information on optimizing latency and resource usage for your specific needs. https://www.dgway.com/market/finance/
Youtube: https://youtu.be/_J8fY9Je-xo
Article about Low-Latency IP Cores