Introduction of NVMeTCP25G-IP 4 sessions with DMA on Alveo U50 Card
The aricle showcases a new solution for data center applications called the accelerator system for NVMe/TCP host function.
We divided it into two parts.
The first part of the article introduces the NVMe/TCP protocol, how it enables the host system to access data stored in NVMe SSDs in the target system, and the standard way to implement it using a standard NIC.
The proposed solution uses the Alveo accelerator card integrated with NVMeTCP25G-IP core, which reduces the load on the CPU and allows for high performance NVMe storage array access as simple as DMA memory access with less CPU load than other systems.
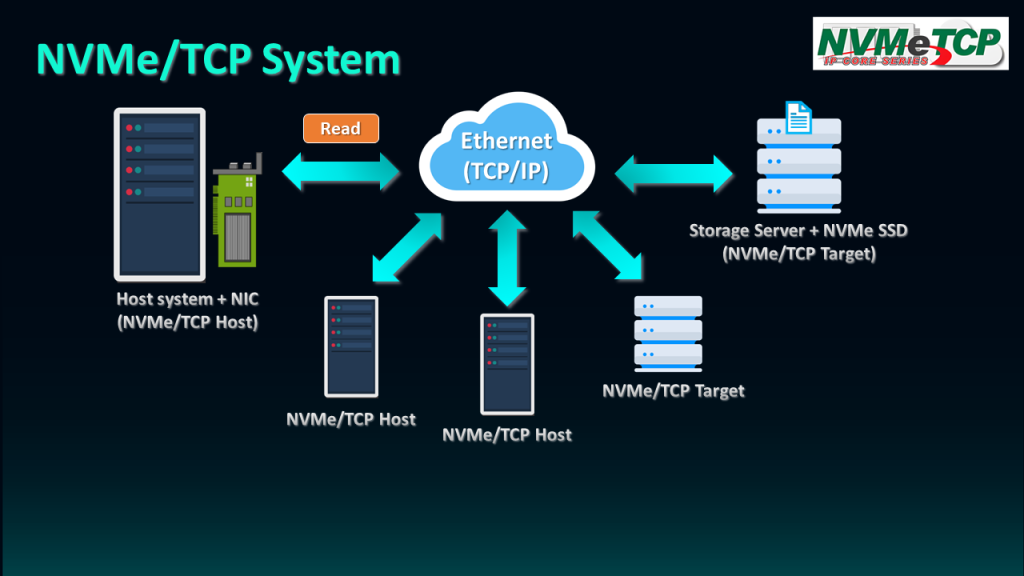
NVMe/TCP is the protocol that enables the Host system to access data stored in NVMe SSDs in the Target system through Ethernet. The Host system can be set up using the Server with an integrated NIC card and NVMe/TCP host driver.
The Target system must integrate NVMe SSD and mount it with the NVMe/TCP target driver to enable remote access via the network. Once connected, the host can send commands such as Read to the Target, which returns the data block to the Host.
The scalability of NVMe/TCP, which is based on TCP/IP protocol, makes it easy to connect multiple hosts and targets to share and exchange data with them.
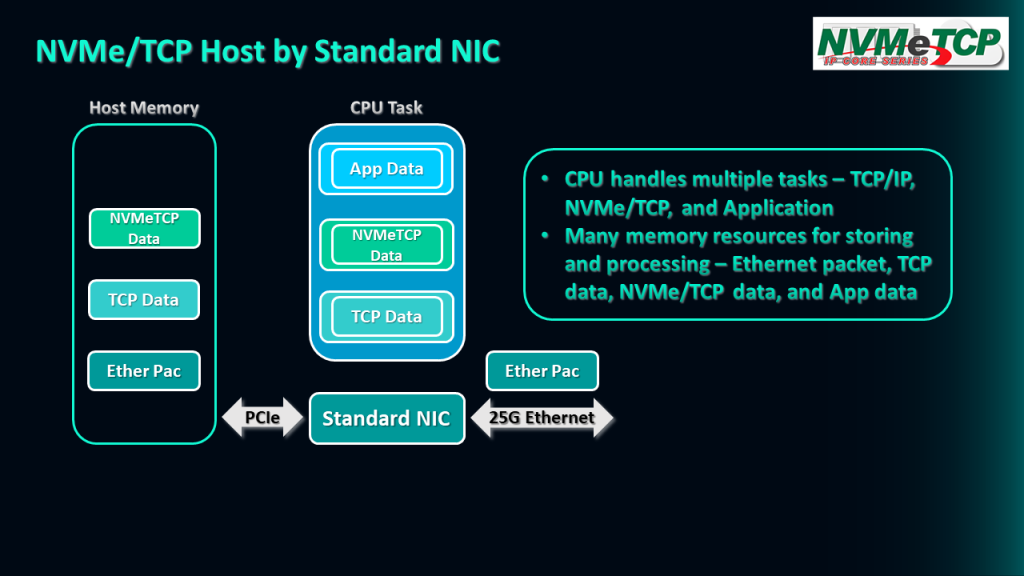
Let me show you an example of how the NVMe/TCP host function works when implemented by a standard NIC. An example of the operation of NVMe/TCP host function by the standard NIC is demonstrated.
Firstly, the standard NIC receives the Ethernet packets from a 25G Ethernet connection and stores them in the Host memory via a PCIe interface.
Then, the CPU executes the TCP/IP stack to extract the TCP payload data from the Ethernet packet and store it in the Host memory.
Next, the CPU operates the NVMe/TCP feature to decode the NVMe/TCP data from the TCP payload data and store the result in the Host memory.
Finally, the application running on the CPU can read and execute the output data of the NVMe/TCP function, with the resulting data stored in the Host memory.
It is important to note that the CPU has to handle multitasks, including the TCP/IP function, NVMe/TCP function, and the application, to complete the NVMe/TCP host operation.
This means that the memory needs to be able to store different types of data, including Ethernet packets, TCP payload data, NVMe/TCP data, and Application data.
Additionally, memory bandwidth can be an issue when processing these tasks in parallel because multiple tasks require simultaneous access to their respective data.
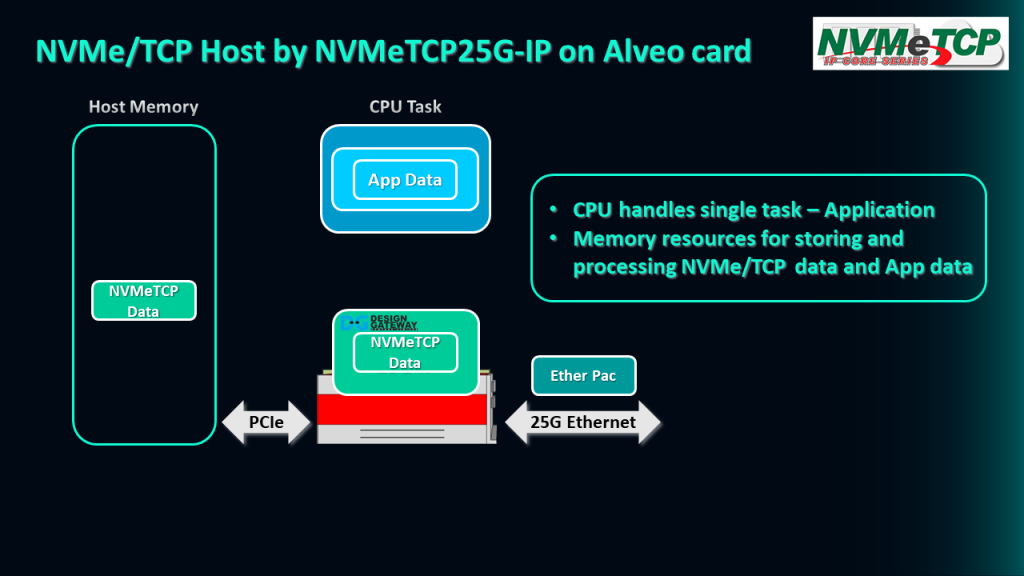
We have proposed a new solution that utilizes the Alveo accelerator card integrated with NVMeTCP25G-IP in this system.
The NVMeTCP25G-IP decodes the Ethernet packet from the 25G Ethernet connection, and the resulting NVMe/TCP data is uploaded to the Host memory via the PCIe interface. By using the Xilinx platform, the NVMe/TCP data can be uploaded to the memory at a very high speed.
The CPU then executes the application to decode and process the data to get the output result. In this system, the CPU only needs to handle a single task, which is running the application.
Furthermore, this system is designed to use memory resources more efficiently, with less access required for storing the NVMe/TCP data and the application data. This approach reduces the load on the CPU and allows for faster data processing.
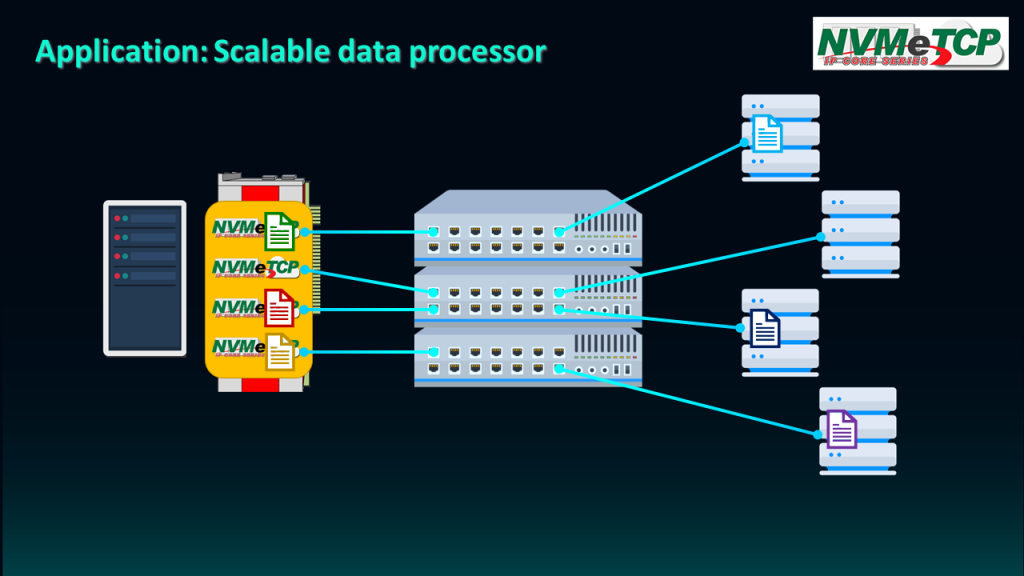
The NVMe/TCP protocol enables seamless sharing of data between hosts and targets over Ethernet, offering a streamlined solution for complex data processing tasks that require multiple offload engines.
In this scenario, we assume the use of four NVMeTCP25G IPs, allowing four engines to access the data source via Ethernet.
The first engine reads the data from the source, processes it, and then stores the result in new storage. With the ability to read data from multiple sources simultaneously, parallel processing by multiple engines is made possible. Once data processing is complete, the results can be returned to the same or different storage as required.
Overall, the NVMe/TCP protocol provides an efficient and reliable solution for data processing tasks that require multiple offload engines, with the added benefits of seamless data sharing and parallel processing capabilities.
For more information Please visit our website: https://dgway.com/index_E.html
Youtube: https://youtu.be/-3zV5oLXU14