Unveiling the Full Potential of 100G Ethernet!
Welcome to TOE100GADV-IP introduction. In this article, we will accompany you to survey our brand new TCP offload engine solution, TOE100G advance.
The FPGA-base IP Core, enabling you to achieve the blazing-fast 100Gigabit Ethernet line rate, even when communicating with CPU-based endpoint.
Effortlessly integrate with its standardized interface and transform your network performance today!
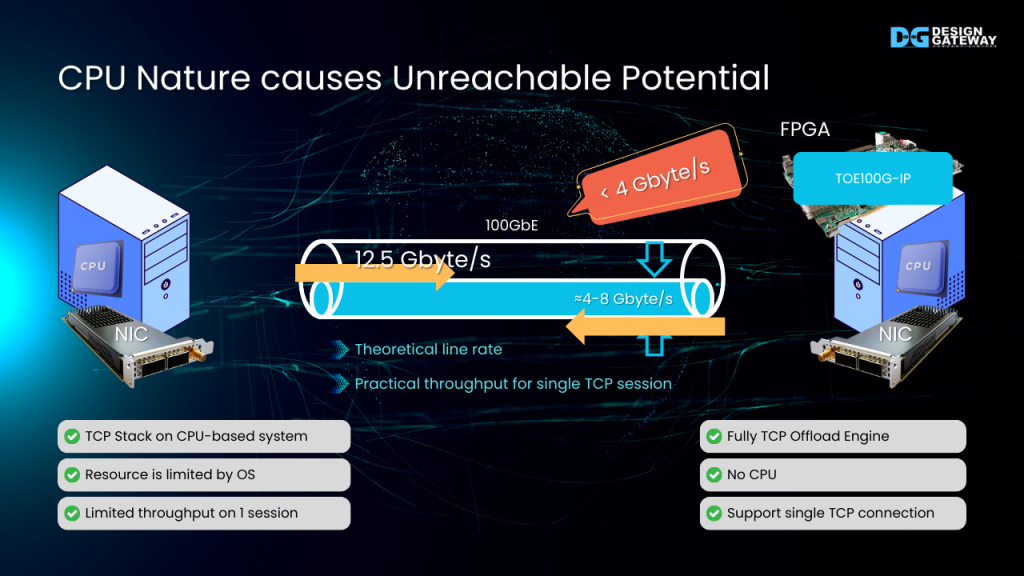
CPU Nature causes Unreachable Potential
100 Gigabit Ethernet emerges as a powerful solution for high-throughput network, addressing the ever-growing demand of data. 12,500 MB/s is the theoretical bandwidth of this Ethernet speed.
However, when used for TCP/IP communication, the practical throughput of a single session on a CPU-based system falls short of expectations. This unimpressive throughput is also unexceptional among the hybrid system between FPGA and CPU.
Design Gateway has introduced the TOE100G-IP Core, a CPU-less solution on FPGA that efficiently handles TCP/IP offloading.
When using TOE100G-IP for one-session data transfer with a CPU-based endpoint, the performance is only around 4,000 to 8,000 MB/s.
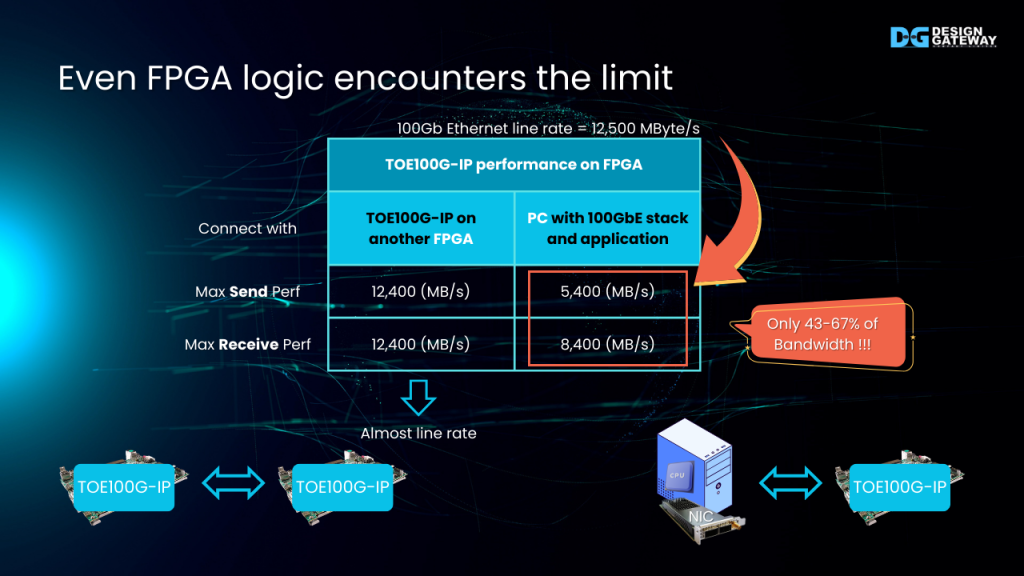
Even FPGA logic encounters the limit
To illustrate, consider the performance results from our TOE100G-IP demonstration. The test uses a single TCP session for data transfer.
When both communication endpoints are FPGAs, the performance is excellent, nearly reaching the 100 Gigabit Ethernet line rate of 12,400 MB/s.
However, when one communication endpoint is replaced with a CPU-based PC, the average performance drops to around 40-60% of the bandwidth. This highlights the challenge of achieving high throughput with CPU-based endpoints.
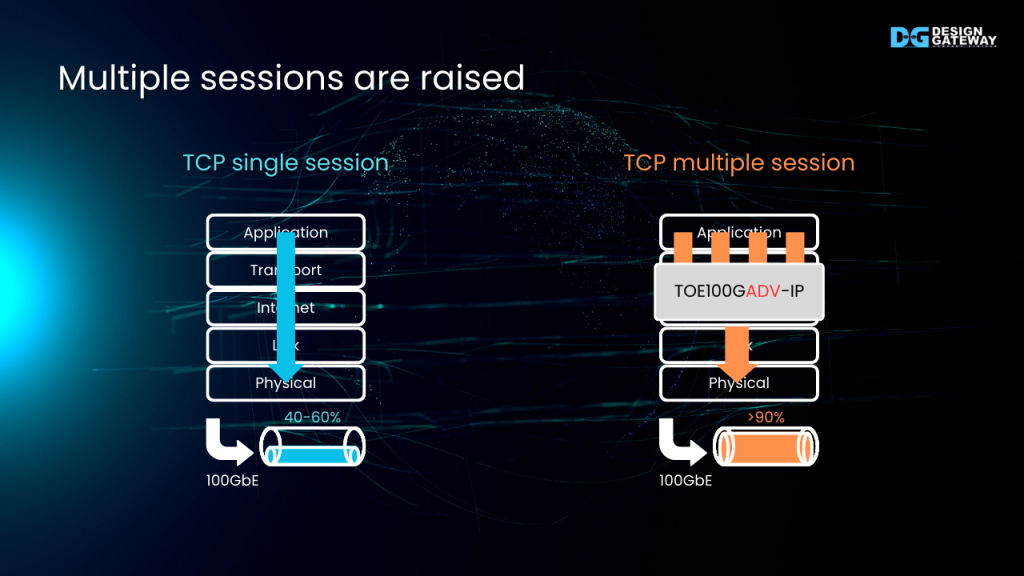
Multiple sessions are raised
Deep down at the end of TCP/IP communication, the acknowledged five layers are presented.
For single TCP connection concept, the data flow from top to down layer is represent as a single line. Gathering the overhead, protocol regulation, and CPU-based behavior, this single line results merely a half of 100 Gigabit bandwidth.
To enhance the throughput, some researches has explored an concept of applying multiple TCP sessions. This approach creates the pipelined data flow in the upper layers, effectively increasing the data volume and utilization of the lower layer bandwidth.
This concept is adopted and proposed as our new IP Core, TOE100GADV-IP which supports up to 4 TCP sessions parallelly.
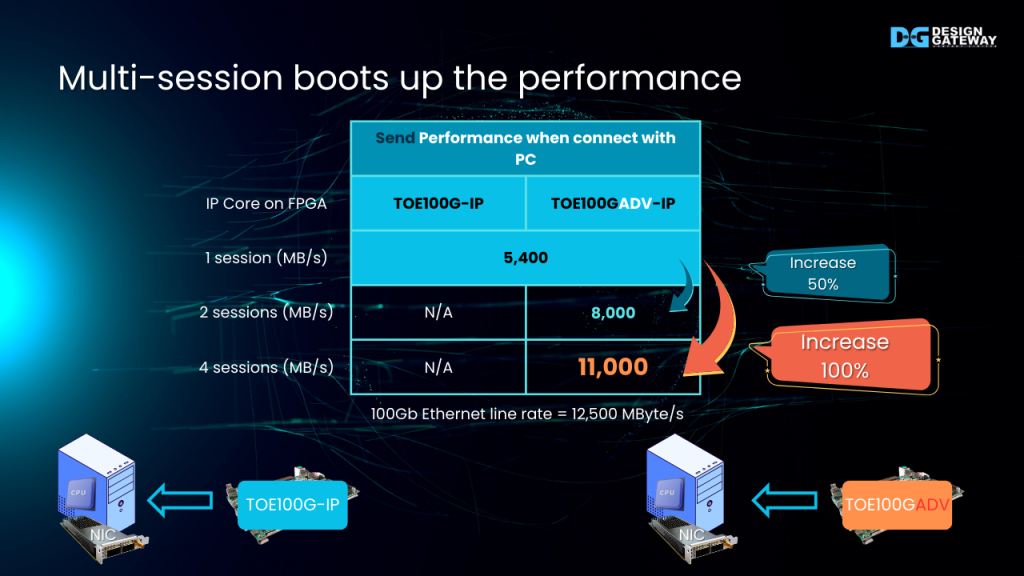
Multi-session boots up the performance
Leveraging the native multi-session capability, the data transfer rate between the FPGA and the CPU-based PC increases proportionally with the number of TCP sessions.

Send performance demo with incremental session
Data from our FPGA console demonstrations confirms the performance gains with TOE100GADV-IP.
With a single active session sending TCP packets to a test PC, the average performance reaches around 5,400 Megabytes per second.
Furthermore, increasing the number of active sessions demonstrably enhances performance: two active sessions achieve 8,000 Megabytes per second, and four active sessions reach 11,000 Megabytes per second.

The best performance easily achieve on FPGA↔FPGA
Despite improving communication with CPU-based endpoints, TOE100GADV-IP maintains its excellent throughput in pure FPGA environments.
The average performance of a single active TOE100GADV-IP session remains comparable to the previous TOE100G-IP, achieving approximately 99% of the 100 Gigabit Ethernet potential.
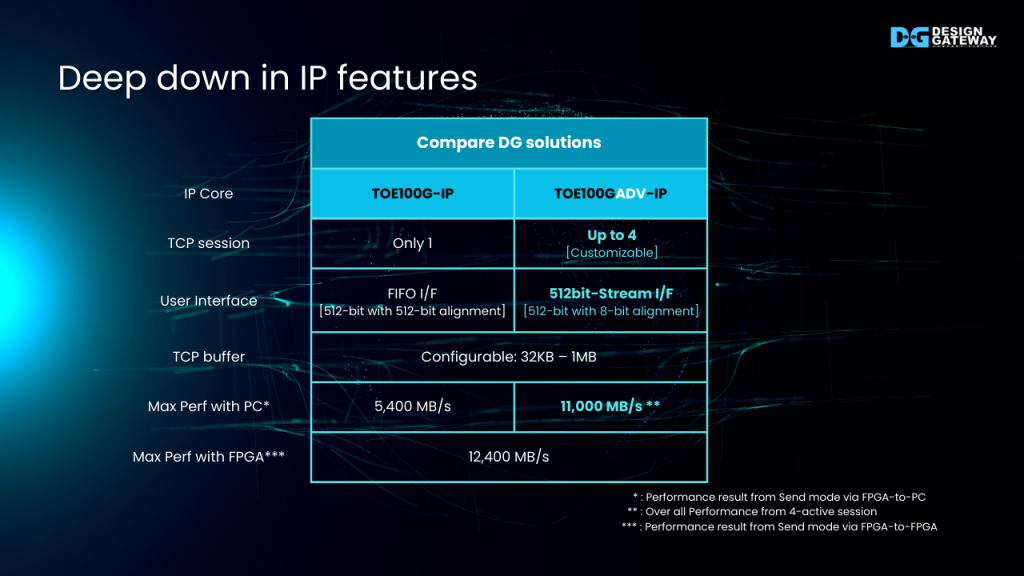
Deep down in IP features
To better understand the features of TOE100GADV-IP, let’s compare it with the previous TOE100G-IP:
Multi-session Support: TOE100GADV-IP offers the native multi-session structure, allowing up to 4 concurrent TCP session.
Standard Interface: TOE100GADV-IP utilizes the 512bit AXI4 and Avalon Stream user interface with byte-alignment support, aligning with the standard interface for FPGA platforms.
Configurable Buffers: Each session in TOE100GADV-IP features independent and configurable TCP buffer sizes.
Maintained FPGA Throughput: Improve the transfer throughput between FPGA and PC while maintaining the excellent throughput in pure FPGA environment.
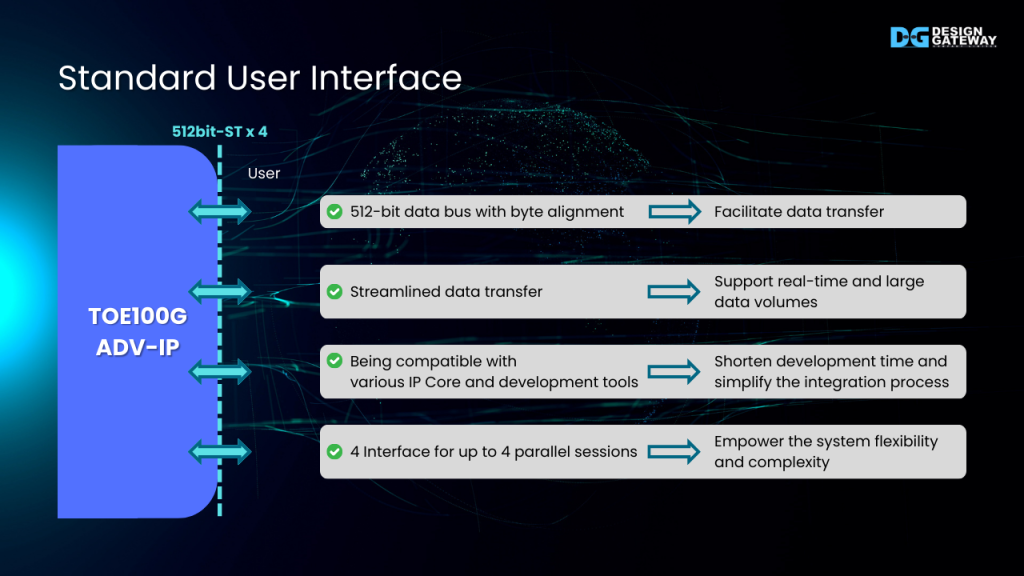
Standard User Interface
The standard user interface provides various advantages in user aspect.
Reduced Limitations: Byte-alignment allows for data transfer with fewer restrictions on data boundaries, enhancing flexibility.
Suitable for High Throughput: The stream interface type is particularly appropriate for handling large data volumes efficiently, aligning with the capabilities of 100 Gigabit Ethernet.
Simplified Development on FPGA Platform: As a widely adopted standard, the AXI4 or Avalon Stream interface streamlines development processes on FPGA platforms.
Increased Flexibility: Each session’s dedicated user interface enhances user solution flexibility by allowing for independent control of multiple concurrent data streams.
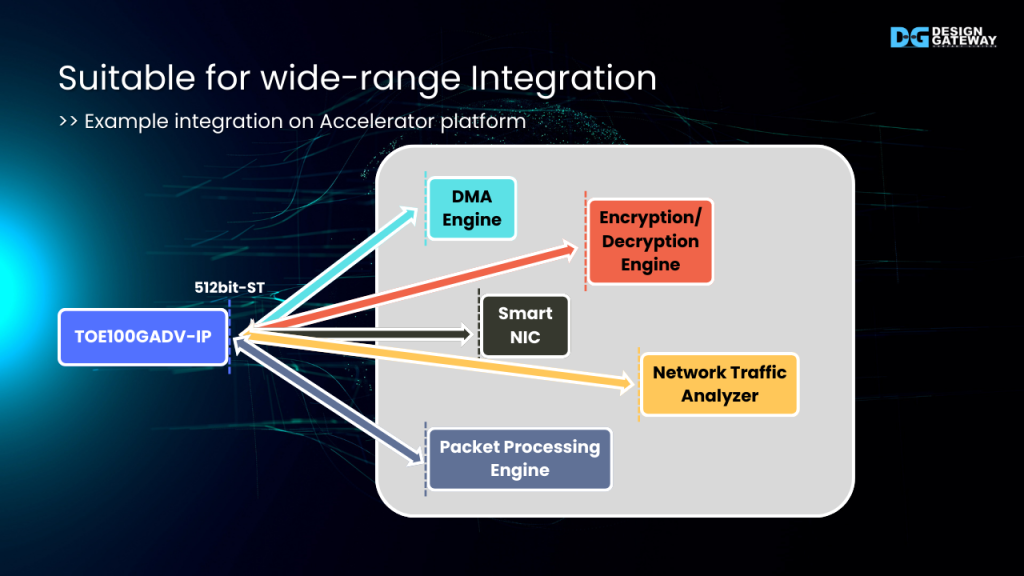
Suitable for wide-range Integration
The 512bit-Stream interface simplifies the integration process of the TOE100GADV-IP, particularly when using FPGA Accelerator platforms. This widely adopted interface allows for seamless cooperation and integration with both High-Level Synthesis and RTL designs.
Here are some potential application examples for TOE100GADV-IP, leveraging its capabilities and the standard interface:
Direct Memory Access (DMA) Engine: Offloads memory transfer tasks from the CPU, improving overall system performance.
Encryption/Decryption Engine: Enables secure network communication by handling encryption and decryption tasks efficiently.
Smart NIC: Integrate with Smart NIC framework to provides the low-latency and high throughput TCP communication channel for competitive performance in your network infrastructure environments.
Network Traffic Analyzer: Facilitates in-depth analysis of network traffic patterns and statistics for network monitoring and optimization purposes.
Packet Processing Engine: Enables efficient filtering, routing, and security checks on network packets.
YouTube: https://youtu.be/t5gQtb0_Dps
Website: https://dgway.com/TOE-IP_X_E.html
Article about TOE-IP





